
研究内容
私の研究は、NAIST コンピューティング・アーキテクチャ研究室で開発された非ノイマン型 CGLA(粗粒度再構成可能論理アレイ)IMAX 上での AI ワークロードの実装・最適化に焦点を当てています。
特に関心があるのは、カーネル単体の高速化と実際の end-to-end 性能の間にあるギャップです。実際のアクセラレータ効率は、演算カーネルだけでなく、ホスト側オーバーヘッド、DMA の振る舞い、メモリ制約、ランタイム方針によって大きく左右されます。そのため、アーキテクチャ、ソフトウェア実装、システム評価を一体として扱う研究を進めています。
研究キーワード
コンピュータアーキテクチャ · ドメイン特化アーキテクチャ · AI アクセラレータ · 非ノイマン型
ハードウェア・ソフトウェア協調設計 · ニアメモリコンピューティング · 省電力・高効率コンピューティング
LLM · 生成AI · 画像生成 · 音声認識 · 深層学習 · エッジAI
研究の視点
- 単独のカーネルではなく、実用的な AI システムとして成立するかを見る
- runtime breakdown やクロスプラットフォーム比較でボトルネックを定量化する
- 一つの実装知見を複数の AI ドメインへ再利用する
- エッジ向け試作からサーバ規模評価へつなげる
NAIST での現在の研究
近年の LLM・生成AIの急速な発展はGPUへの需要を爆発的に増加させています。しかしGPUは本質的に電力効率を突き詰めた設計ではなく、膨大なメモリ帯域によって性能を確保しています。これはAIの持続的な発展を支える基盤として限界があります。
私は、フォン・ノイマン・ボトルネックを構造的に排除した非ノイマン型コンピューティングの普及が最も現実的かつインパクトの大きい次の一手であると考えています。ニアメモリ・インメモリコンピューティングとソフトウェアの協調設計によってこれを実現することが研究の目標です。
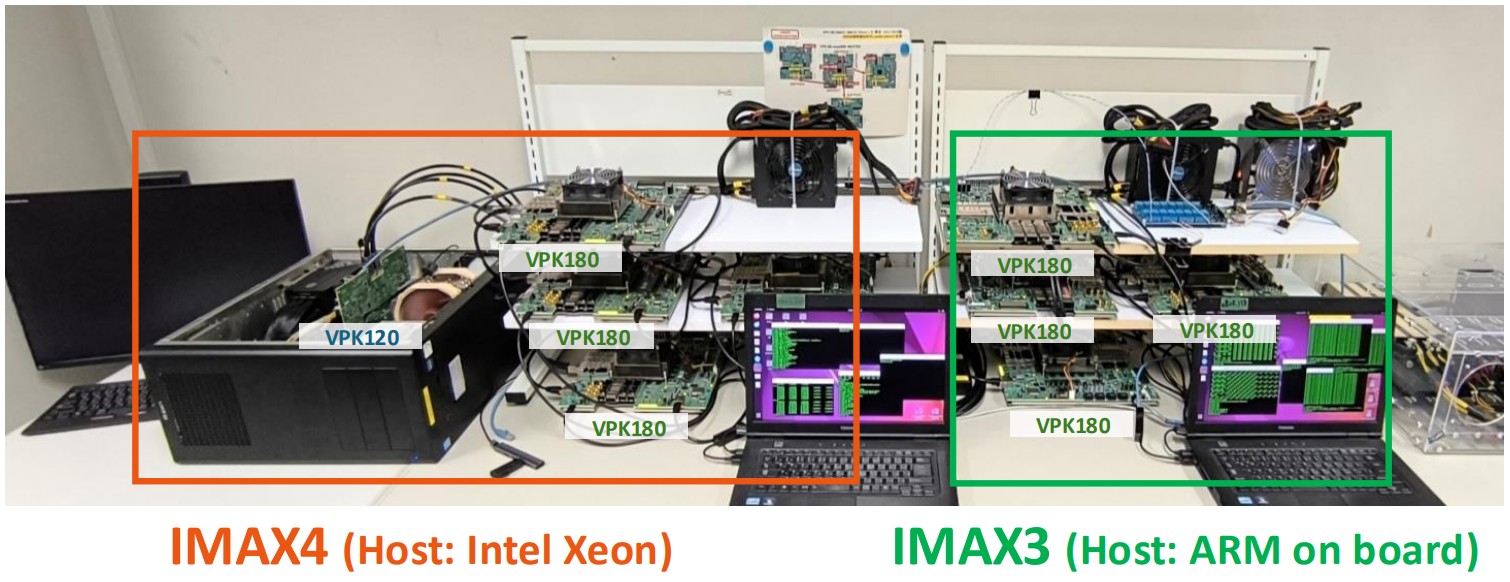
IMAX3/IMAX4 上での LLM 高速化
IMAX 上で Llama3・Qwen・Flan-T5 を実行し、詳細なボトルネック分析を実施。ホスト CPU と PCIe 帯域の制約を特定し、高性能サーバ CPU と PCIe Gen5 を搭載した IMAX4 の設計・評価によりサーバ規模のAIワークロードへのスケーラビリティを実証。

発表: IEEE Access (2025), SOCC 2025, SASIMI 2025 [Young Researcher Award], ICISN 2026 [Best Paper]
主な成果: 28nm 見積評価で RTX 4090 比 44.4 倍の PDP 改善、Q-Snap による 1.62 倍の prefill 高速化、IMAX4 移行による大幅なホスト側オーバーヘッド削減。
生成AI — Stable Diffusion の IMAX 実装
Stable Diffusion を IMAX 上に実装し、CGLA アーキテクチャがテキスト生成以外の多様な生成 AI ワークロードにも対応できることを実証。
発表: MCSoC 2025
着眼点: LLM 向けに構築した量子化カーネルを画像生成へどこまで再利用できるか、また F16 / F32 演算がどこで制約になるかを明らかにすること。
音声認識 — Whisper の IMAX 実装
Whisper ASR を IMAX に実装し、独自の FP16 演算カーネルを開発。省電力推論を実現しながら CGLA の汎用性を実証。
発表: CANDAR 2025 [Best Paper]
着眼点: ホスト CPU と IMAX の混合実行、独自 FP16 カーネル設計、モデルサイズや量子化設定をまたいだ電力効率評価。
高専での研究
物体検出 — 小ねぎ分岐部検出
エッジデバイス上での小ねぎ自動調製向け分岐部検出アルゴリズムを開発。古典的エッジ検出と YOLO・Mask-RCNN 深層学習を組み合わせ、リソース制約デバイス上での精度と軽量化を両立した。
AI 推論の FPGA 実装 — 表情認識システム
DPU ベースの DNN アクセラレータを用いた時分割マルチタスクにより、単一ハードウェア上で2つの DNN モデルを実行するシステムを実装。組み込み CPU と比較して優れたフレームレートと電力効率を実証。

現在の関心
直近では、異種 AI ワークロードを支える統合ソフトウェアスタック、SSM や新しい LLM 系モデルの効率実行、アクセラレータ研究を再現しやすく比較しやすくするためのシステム評価手法に強い関心があります。